
Cases and their attributes are powerful features in NVivo. They facilitate comparisons between your research participants (or other entities) and can reveal patterns and insight in your data. This post helps you assess whether cases would be useful for your project and provides a roadmap for setting them up.
A sample scenario
Let’s say you’ve interviewed members of a local community to see how they are responding to the effects of climate change.
You import the interview transcripts into NVivo and get started with some preliminary thematic coding.
All sorts of interesting themes start to emerge - ideas about tourism, real estate development and water quality just to name a few.
As you peel back the layers you begin to wonder:
- Do males and females see these issues differently?
- Does a person’s age have an impact on his/her perceptions?
- Do long term residents have different attitudes from new comers?
To answer these questions, you need access to the relevant demographic variables for each participant– in NVivo, you do this via cases.
What is a case?
A case is a special type of node (or container) that holds all the coded content about a person, place, organization or other unit of analysis:
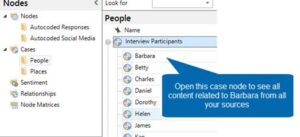
Like a theme node, a case node holds coded content but it also has descriptive attributes.
For example, Barbara’s case node has attributes for things like Gender, Age Group and Generations Down East:
Why do I keep putting the word coded in italics?
Because, coding is the way you get the content about a person into his/her case node. For example, you select all the content in Barbara’s interview transcript and code it at the Barbara case node.
You could do this manually for each transcript but NVivo offers ways to speed this up – you’ll find out more about this in the roadmap below.
Creating cases – a roadmap
There are a few steps involved in setting up cases and these may be slightly different depending on what sort of data you're working with.
For example, if you have focus group transcripts with multiple participants - you can follow the first five steps of the roadmap to create a classification and its attributes but then you'll need to manually create a case for each focus group participant and then go through the transcript to code responses at all the relevant cases.
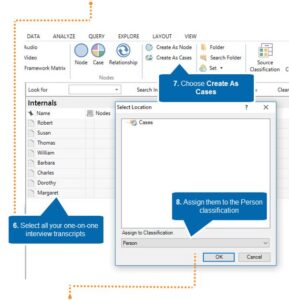
If your transcripts are one-on-one interviews (like those in our scenario), you can follow this roadmap from start to finish:
Create a new classification
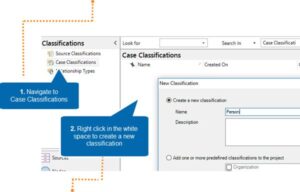
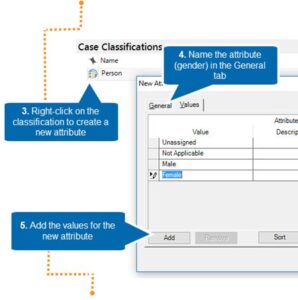
Add the attributes
Create cases from one-on-one interviews
Add the attribute values
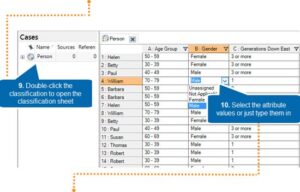
Your cases are ready, now unleash the power of queries
As your thematic coding progresses you can use queries to make comparisons based on case attributes.
For example, you could run a Matrix Coding query to compare what people from different age groups say about real estate development or compare what men and women say about tourism.
Alternatively, you could use a Comparison Diagram to compare the coding in two of your cases.
Do you already have demographic data in a spreadsheet?
If you have an Excel spreadsheet (or a text file) containing information about your participants - you can import it into NVivo.
Based on the classifying details in your spreadsheet, NVivo can automatically apply attributes to the cases you have created for your participants. Just make sure that case names in the spreadsheet match those in your project.
Working with different types of cases
A study might also involve more than one type of case. For example, the climate change project has case classifications for:
- Person; with attributes age, gender, community and so on.
- Place; with attributes for population, average tax value and driving time to the nearest city.
When planning your research project, you should think about your own units of analysis and decide whether you need cases and which kind will best support your research goals.
“It all depends on your research questions, and the data you collect to answer those questions. Your case structure in NVivo should follow your research design, not lead it.” (Bazeley and Jackson, 2013, p.51)
Working with survey data
If you’re working with surveys rather than interviews, the process for setting up cases is a little different.
In NVivo Pro and Plus you can import a survey and NVivo will automatically create cases and apply demographic attributes based on the classifying data in your survey.
This video gives you a heads-up on how that works:
What kind of cases are you working with? We'd love to hear about your experiences in the comments below.
References
Pat Bazeley & Kristi Jackson.(2013) Qualitative Data Analysis with NVivo .SAGE Publications. Kindle Edition.
ABOUT THE AUTHOR

Kath McNiff
Kath McNiff is on a mission to help researchers deliver robust, evidence-based results. If they’re drowning in a sea of data (or floods of tears) she wants to throw them an NVivo-shaped life raft. As an Online Community Manager at QSR, she knows that peers make the best teachers. So, through The NVivo Blog, Twitter and LinkedIn, she shares practical advice and connects researchers so they can help each other. When she’s not busy writing blog posts, swapping stories on social media or training the latest tribe of NVivo users, she can be found wrestling four feisty offspring for control of the remote.